Full-body High-resolution Anime Generation with
Progressive Structure-conditional Generative Adversarial Networks
Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto Honda, and Yusuke Uchida
DeNA Co., Ltd., Tokyo, Japan
[Paper][ArXiv][Generated Anime 1][Generated Anime 2]
Artwork and paper have been accepted to
the ECCV Workshop on Computer Vision for Fashion, Art and Design, 2018.
- May 11, 2018: Project page launched.
- September 6, 2018: Submitted to arXiv.
- September 6, 2018: Generated animes updated to 1024x1024 res.
- September 14, 2018: Plan to present at the ECCV Workshop on Computer Vision for Fashion, Art and Design, 2018.
Abstract
We propose Progressive Structure-conditional Generative Adversarial Networks (PSGAN), a new framework that can generate full-body and high-resolution character images based on structural information. Recent progress in generative adversarial networks with progressive training has made it possible to generate high-resolution images. However, existing approaches have limitations in achieving both high image quality and structural consistency at the same time. Our method tackles the limitations by progressively increasing the resolution of both generated images and structural conditions during training. In this paper, we empirically demonstrate the effectiveness of this method by showing the comparison with existing approaches and video generation results of diverse anime characters at 1024x1024 based on target pose sequences. We also create a novel dataset containing full-body 1024x1024 high-resolution images and exact 2D pose keypoints using Unity 3D Avatar models.
Full-body Anime Generation at 1024x1024
We show examples of a variety of anime characters and animations at 1024x1024 resolution generated by Progressive Structure-conditional Generative Adversarial Networks (PSGAN) with test pose sequences. 1. We first generate many anime characters using our network from random latent variables and create new characters by interpolating them. 2. Next we give continuous pose sequence information to the network to generate an animation video for each character. In this video we repeat 1 and 2 several times.
Generation of new Full-body Anime Characters

We generate new full-body anime characters by interpolating latent values corresponding to anime characters with different costumes (character 1 and 2) with PSGAN. Note that only a single pose condition is imposed here.
Adding Action to Full-body Anime Characters
The following shows examples of animation generation with the specified anime characters and target pose.
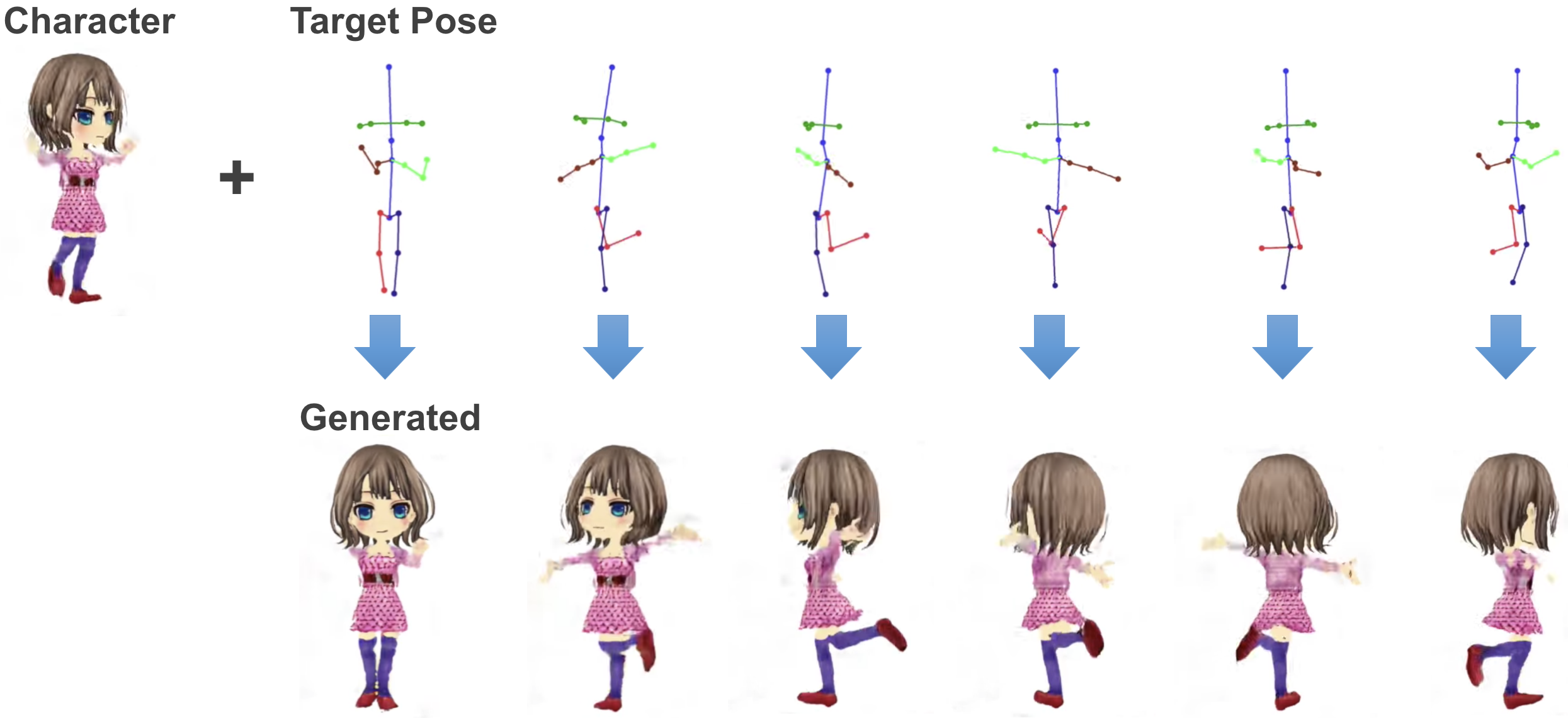
By fixing the latent variables and giving continuous pose sequences to PSGAN, we can generate an animation for each character. More specifically, we map the representation of the specified anime character into the latent variables in the latent space which serve as the input vector of PSGAN.
By mapping the specified anime characters to latent space and generating the latent variables as the input of PSGAN, arbitrary animation with the specified anime characters is generated.
Progressive Structure-conditional GANs (PSGAN)
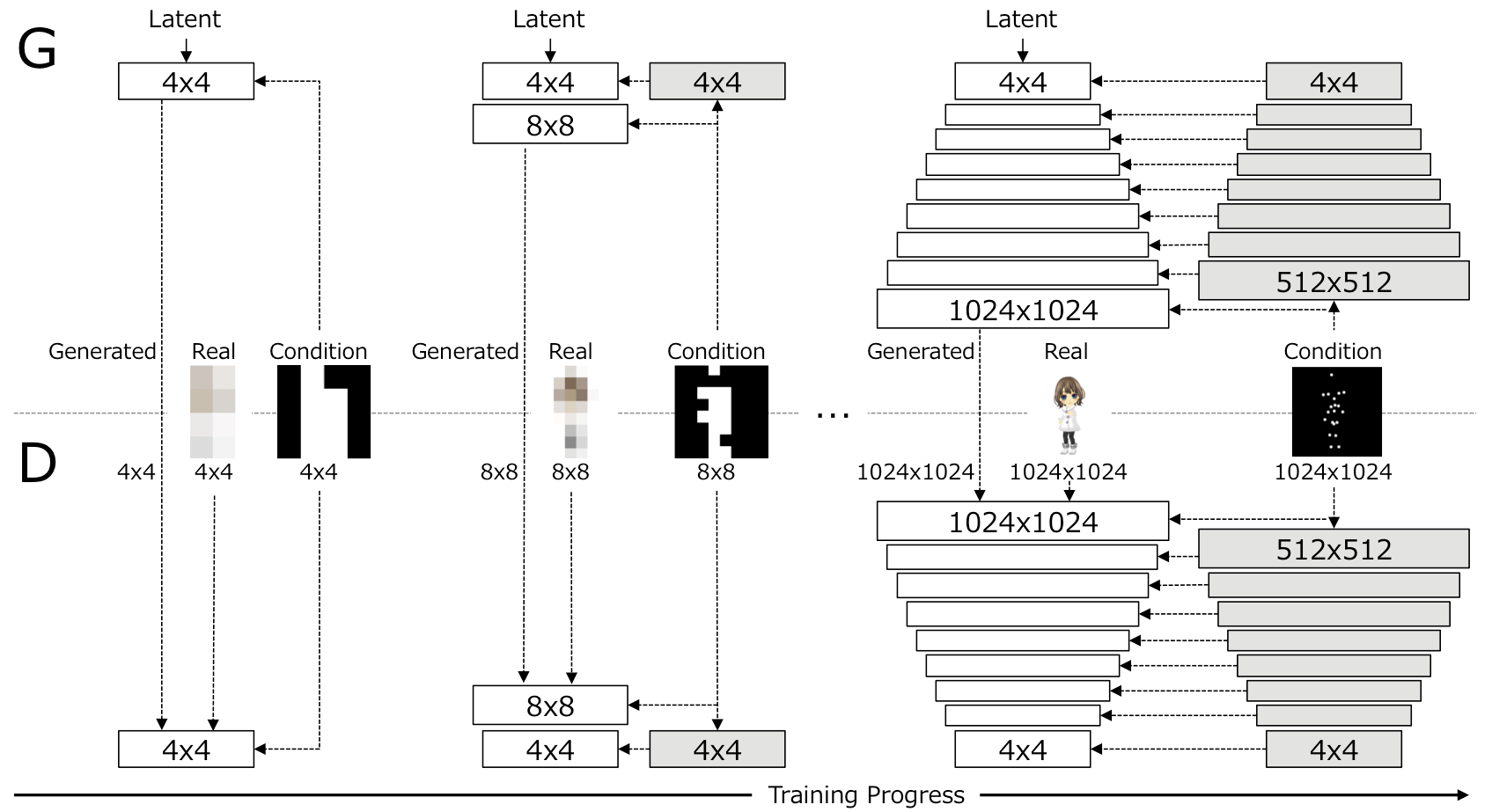
Our key idea is to learn image representation with structural conditions progressively. The above figure shows generator G and discriminator D architecture of PSGAN. PSGAN increases the resolution of generated images with structural conditions at each scale and generates high-resolution images. We adopt the same architecture of the image generator and discriminator as Progressive GAN [Karras+18], except that we impose structural conditions on both the generator and discriminator at each scale by adding pose maps with corresponding resolutions, which significantly stabilizes training. GANs with structural conditions have also been proposed [Ma+17,Ma+18,Balakrishnan+18,Siarohin+18,Si+18,Hu+18,Qiao+18]. They exploit a single-scale condition while we use multi-scale conditions. More specifically, we downsample the full-resolution structural condition map at each scale to form multi-scale condition maps. For each scale, the generator generates an image from a latent variable with a structural condition and the discriminator discriminates the generated images and real images based on the structural conditions. NxN white boxes stand for learnable convolution layers operating on NxN spatial resolution. NxN gray boxes stand for non-learnable downsampling layers for structural conditions, which reduce spatial resolution of the structural condition map to NxN. We use M channels for representation of M-dimensional structural conditions (e.g. M keypoints).
Avatar Anime-Character Dataset
We create a novel dataset containing full-body 1024×1024 high-resolution images and exact 2D pose keypoints using Unity 3D Avatar models, which consists of 600 poses and 69 kinds of costumes. The following figure shows samples of created data. Anime characters (left of pair) and pose images (right of pair) are shown.

Comparisons

Comparison of structural consistency

The above figure shows generated images on the DeepFashion dataset [Liu+16] (256x256) by Progressive GAN [Karras+18] and PSGAN. We observe that Progressive GAN is not capable of generating natural images consistent with their global structures (for example, left four images). On the other hand, PSGAN can generate plausible images consistent with their global structures by imposing the structural conditions at each scale.
Comparison of generated image quality based on pose conditions
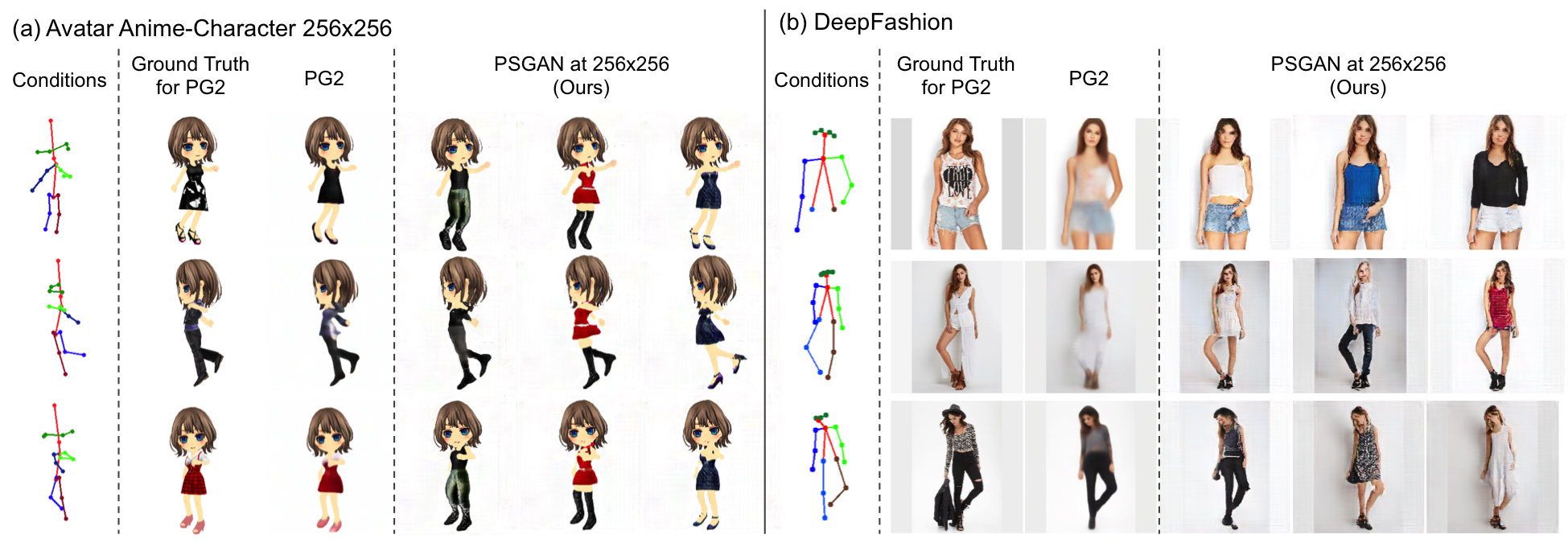
The above figure shows generated images of PSGAN and Pose Guided Person Image Generation (PG2) [Ma+17] on the 256x256 resolution version of the Avatar dataset and DeepFashion dataset. We can observe the generated images of PSGAN are less blurry and more detailed than PG2 due to structural conditions imposed at each scale.
PG2 requires a source image and a corresponding target pose to convert the source image to an image with the structure of the target pose. Meanwhile, PSGAN generates an image with the structure of the target pose from latent variables and the target pose and does not need paired training images.
Citation
@inproceedings{hamada2018anime,
author = {Koichi Hamada and Kentaro Tachibana and Tianqi Li and Hiroto Honda and Yusuke Uchida},
title = {Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks},
booktitle = {Proc. of ECCV Workshop on Computer Vision for Fashion, Art and Design},
year = {2018}
}
References
[Karras+18] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, and Stability, and Variation. In ICLR, 2018.
[Ma+17] Liqian Ma, Qianru Sun, Xu Jia, Bernt Schiele, Tinne Tuytelaars, and Luc Van Gool. Pose Guided Person Image Generation. In NIPS, 2017.
[Ma+18] Liqian Ma, Qianru Sun, Stamatios Georgoulis, Luc Van Gool, Bernt Schiele, and Mario Fritz. Disentangled Person Image Generation. In CVPR, 2018.
[Balakrishnan+18] Guha Balakrishnan, Amy Zhao, Adrian V. Dalca, Fredo Durand, and John Guttag. Synthesizing Images of Humans in Unseen Poses. In CVPR, 2018.
[Siarohin+18] Aliaksandr Siarohin, Enver Sangineto, Stephane Lathuiliere, and Nicu Sebe. Deformable GANs for Pose-based Human Image Generation. In CVPR, 2018.
[Si+18] Chenyang Si, Wei Wang, Liang Wang, and Tieniu Tan. Multistage Adversarial Losses for Pose-Based Human Image Synthesis. In CVPR, 2018.
[Hu+18] Yibo Hu, Xiang Wu, Bing Yu, Ran He, and Zhenan Sun. Pose-Guided Photorealistic Face Rotation. In CVPR, 2018.
[Qiao+18] Fengchun Qiao, Naiming Yao, Zirui Jiao, Zhihao Li, Hui Chen, and Hongan Wang. Geometry-Contrastive Generative Adversarial Network for Facial Expression Synthesis. arXiv preprint arXiv:1802.01822, 2018.
[Liu+16] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In CVPR, 2016.
[Unity] Unity, https://unity3d.com